On June 16th I gave the following short talk at Harvard’s Institute for Quantitate Social Sciences before I was on a panel with Victoria Stodden, Thomas Leeper, and Margo Seltzer as part of the 2017 Dataverse Community Meeting. The discussion centered around the “researcher fatigue” that some experience when they’re unwilling to use computational tools for reproducible research. You can find the slides for this talk here. The source code for this blog post is a little different than usual, if you’re interested you can find it here.

I was thinking about the topic for this panel, and I started imagining some of the potential uses for a data repository like Dataverse beyond the features it already offers.

In the beginning of the reproducible research movement sharing data, code, and other research artifacts was a hard problem.

Thankfully the right investments in infrastructure were made and now we have resources like Dataverse!

However at the same time many other file storage services proliferated making it easy to just throw files and code online without the well thought out structure of an academic data repository.

The “throwing files online” approach is currently the least fatiguing path! My boss Jeff Leek (pictured here) just wrote a blog post championing just posting plain text files online. If you just put your data on your website then nobody has to log in to a platform, theoretically they can have the data in their computing environment with a URL and one line of code.

My question is - what kind of value can a data repository provide beyond being a place to make data available?

Well thankfully we have the tools of open science available to us in a data repository! We have ORCiD IDs, DOIs, and all of the metadata that our datasets are labelled with. What if we used these resources to make a data repository a destination for discovering new research, datasets, and potential collaborations?

Here's a screenshot from my recent front page of Amazon.com of books I might be interested in. Clearly this is the result of a clustering algorithm, based on the books I've looked at or purchased in the past. These kinds of recommender systems have become off-the-shelf technology in the last few years, and you could imagine how incorporating a recommender system into a data repository might help users discover research. We're collecting so much metadata about the datasets going into these repositories, why not use that metadata in order to suggest other datasets that a researcher might be interested in?

What if we thought about a data repository as a kind of meta-data product?

We've recently been working on a project that's similar in spirit in the Johns Hopkins Data Science Lab. We've been working with Lucy and Nick, both PhD students in the Biostatistics Department at Vanderbilt University.
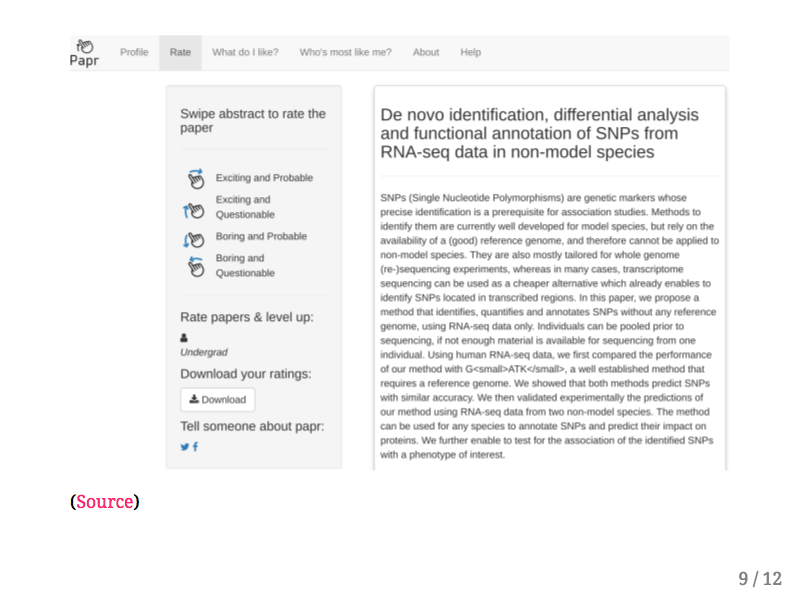
They've developed a web application called Papr, which shows you abstracts bioRxiv pre-prints. You can swipe left on an abstract if you don't like the paper, or swipe right if you do like the paper.
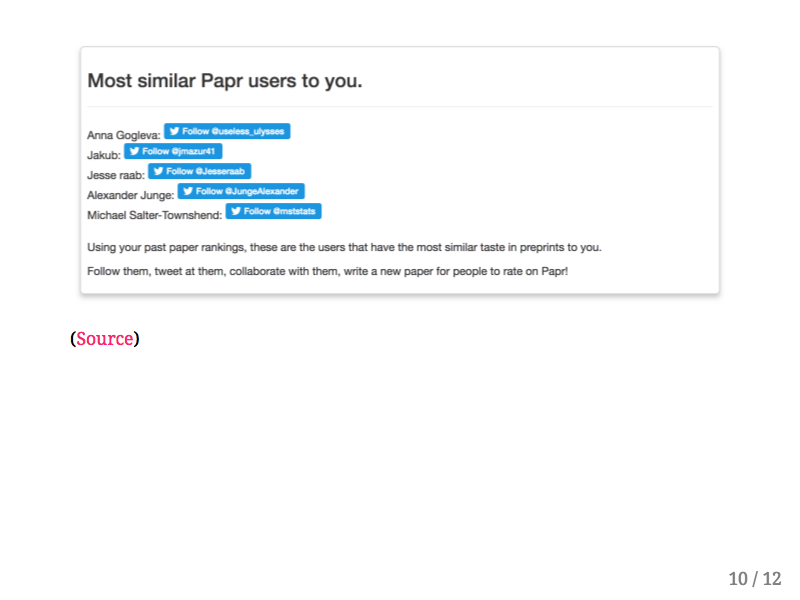
Based on metadata for each pre-print we're able to construct a paper-space where we can match you with researchers who have similar interests.

My hope and my proposal is that we can take ideas from other technology products to make reproducible research tools more user-focused, so that users will making their research reproducible. Perhaps one day the idea of researcher fatigue will seem as foreign as puppy fatigue!
Thank you!