I just got back from rOpenSci’s Unconf which was an absolutely amazing experience! I’m working on a full write up of the conference but while I was there I was able to hang out with Vanderbilt University Biostatistics PhD student Lucy D’Agostino McGowan. Lucy is the Co-founder of R-Ladies Nashville, the Co-founder of the fantastic Live Free or Dichotomize blog, and the Co-creator of papr, a Tinder-like Shiny app for bioRxiv preprints.
Lucy is notorious for using emojis in her Git commit messages, so I wanted to find out which emojis she uses most often. I combined the magic of the GitHub API and the tidyverse to find out!
library(gh)
library(purrr)
library(stringr)
library(git2r)
library(dplyr)
library(ggplot2)
library(gridSVG)
# Get all of Lucy's personal repos
lucy_repos <- gh("/users/LucyMcGowan/repos", .limit = Inf) %>%
map_chr(~ .x$name)
# Get all of Lucy's organizations
lucy_orgs <- gh("/users/LucyMcGowan/orgs", .limit = Inf) %>%
map_chr(~ .x$login) %>%
c("ropenscilabs")
# Get all of the repos that belong to Lucy's organizations
# Then filter out repos that Lucy hasn't contributed to
lucy_orgs_repos <- map(lucy_orgs,
~ gh(paste0("/orgs/", .x, "/repos"), .limit = Inf)) %>%
map(function(org){
map_chr(org, ~ .x$full_name)
}) %>%
unlist() %>%
keep(~ "LucyMcGowan" %in% (
gh(paste0("/repos/", .x, "/contributors"), .limit = Inf) %>%
map_chr(function(user){
ifelse(is.list(user), user$login, "")
})
))
# Combine Lucy's personal repos and her org repos
lucy_repos <- setdiff(lucy_repos, str_extract(lucy_orgs_repos, "[^/]+$")) %>%
paste0("LucyMcGowan/", .) %>%
c(lucy_orgs_repos)
# Download all of the repos Lucy contributes to
dir.create("lucy")
local_repos <- map_chr(str_split(lucy_repos, "/"), paste,
collapse = .Platform$file.sep) %>%
paste0("lucy", .Platform$file.sep, .)
walk(local_repos, dir.create, recursive = TRUE)
walk2(lucy_repos, local_repos,
~ clone(paste0("https://github.com/", .x, ".git"),
local_path = .y))
# Get all commits from Lucy's repos
all_commits <- map(local_repos, repository) %>%
map(~ as(.x, "data.frame")) %>%
bind_rows()
# Filter out all commits except those made by Lucy
lucy_commits <- all_commits %>%
filter(author %in% c("Lucy", "Lucy D'Agostino McGowan", "LucyMcGowan"))
# Get frequency of emoji use across commits
emoji_tbl <- lucy_commits$message %>%
str_extract_all("[\\uD83C-\\uDBFF\\uDC00-\\uDFFF]+") %>% unlist() %>%
str_split("") %>% unlist() %>%
table() %>% sort(decreasing = TRUE) %>% as.data.frame()
colnames(emoji_tbl) <- c("Emoji", "Frequency")
# Plot emoji use!
ggplot(emoji_tbl, aes(Emoji, Frequency)) +
geom_col() +
theme_light(base_size = 30)
grid.export("gglucy.svg")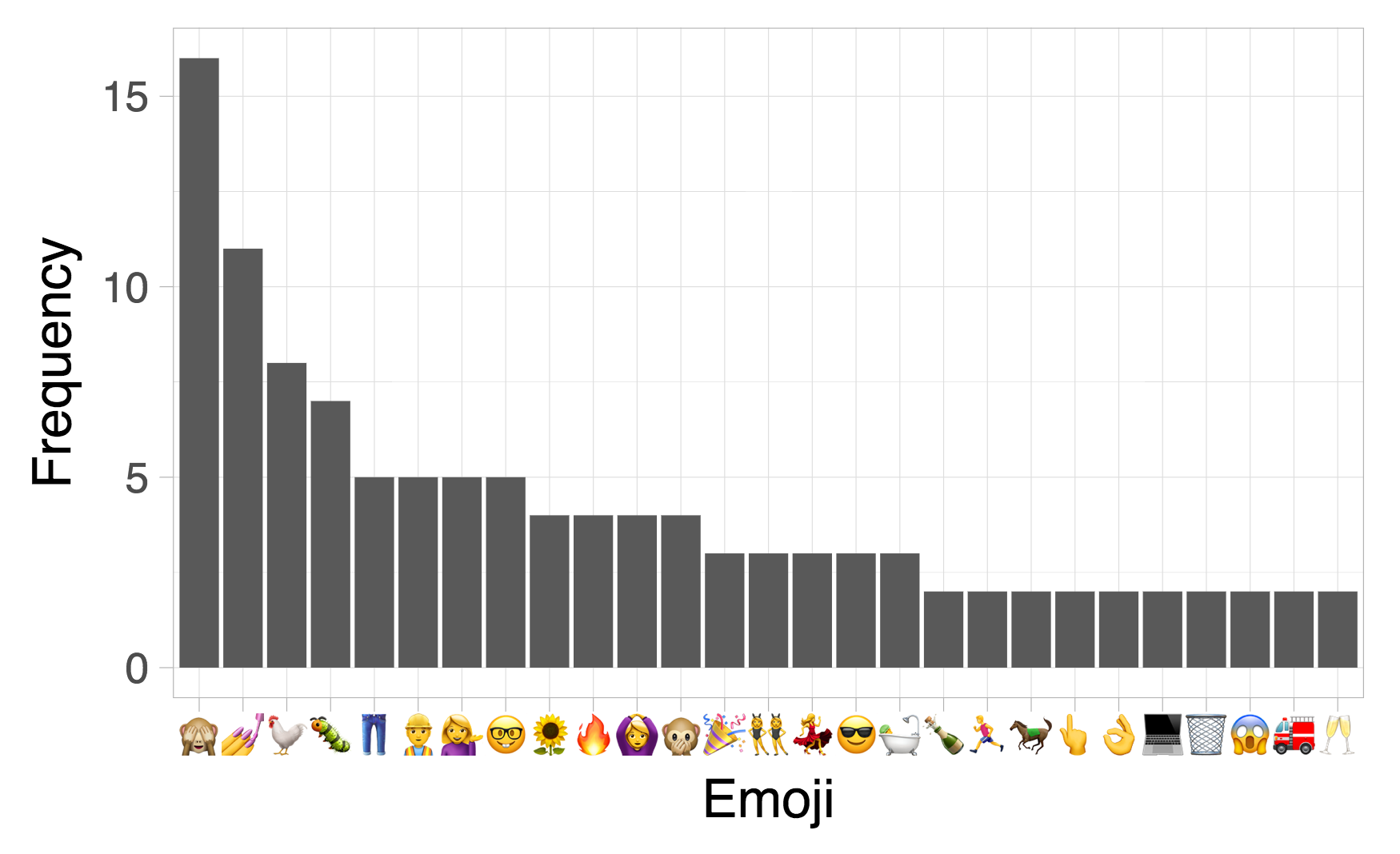
Strong showings by the see-no-evil monkey, the rooster, and the classic information desk woman. Next I wondered: What words in commit messages co-occur most often with certain emojis? Tidytext to the rescue!
library(tidytext)
library(widyr)
lucy_tokens <- lucy_commits %>%
mutate(Emoji = str_extract_all(message,
"[\\uD83C-\\uDBFF\\uDC00-\\uDFFF]+")) %>%
select(message, sha, Emoji)
lucy_tokens <- lucy_tokens %>%
select(-Emoji) %>%
unnest_tokens(word, message) %>%
left_join(lucy_tokens) %>%
mutate(Emoji = map_chr(Emoji, ~ ifelse(length(.x) > 0, .x[[1]], ""))) %>%
filter(!(Emoji %in% c("", "-")))
emo_shas <- lucy_tokens %>%
select(sha, Emoji) %>%
distinct() %>%
rename(word = Emoji)
lucy_tokens %>%
select(sha, word) %>%
bind_rows(emo_shas) %>%
pairwise_count(word, sha, sort = TRUE) %>%
filter(item1 %in% unique(lucy_tokens$Emoji)) %>%
group_by(item1) %>%
slice(1:2) %>%
ungroup() %>%
filter(nchar(item2) > 2) %>%
arrange(desc(n)) %>%
knitr::kable()| n | ||
|---|---|---|
| 🐛 | fix | 5 |
| 🙈 | spell | 4 |
| 🙈 | correctly | 4 |
| 👖 | add | 3 |
| 💅🏼 | add | 3 |
| 🙊 | update | 3 |
| 🙊 | ignore | 3 |
| 🌻 | some | 2 |
| 🎉🐓 | first | 2 |
| 🎉🐓 | commit | 2 |
| 🐓 | add | 2 |
| 🐓 | and | 2 |
| 👆🏼 | make | 2 |
| 👆🏼 | clickable | 2 |
| 👌🏼 | add | 2 |
| 👌🏼 | pca | 2 |
| 👷 | fix | 2 |
| 👷 | update | 2 |
| 💁🏻 | update | 2 |
| 💁🏻 | commit | 2 |
| 💅🏼 | update | 2 |
| 🤓 | fix | 2 |
| 🙆🏻 | add | 2 |
| 🙆🏻 | about | 2 |
| 🚒 | update | 2 |
| 🚒 | recommender | 2 |
If you want to add emojis to your own commit messages Lucy has a great tip:
cmd + ctrl + space to include emojis in the mac terminal 🐓🍻🐙 https://t.co/Iwde1QFtpy pic.twitter.com/BhmWuB1XbE
— Lucy (@LucyStats) May 4, 2017
Update: Scooped!
It seems that statistician and wonderful R blogger Maëlle Salmon had the same idea before me and wrote a very similar blog post!